Published on Mon Jan 20 2025 00:00:00 GMT+0000 (Coordinated Universal Time) by Kristin Wei
If you are curious, there is a link to the AI Camp Event I joined. AI Camp is good in a way that it provides a platform to learn with other in Discord together.
This post consists of 4 parts.
- What is LLM?
- What is RAG?
- What is ReAct?
- Demo of Traditional RAG and Agentic RAG, ReAct Agent
Let’s start it.
What is LLM?
LLM stands for Large Language Model. It is an artificial intelligence system trained on vast amounts of text data to understand and generate human-like language. Some famous examples are:
- ChatGPT: A generative AI chatbot developed by OpenAI
- Claude: A generative AI chatbot developed by Anthropic
- Bard: A language model developed by Google
- Llama: A language model developed by Meta
They are “large” in two ways:
- massive amounts of training data
- billions or even trillions of parameters
Prompt Techniques
There are some prompt techniques (yes, prompt engineering is still important):
- Zero-shot prompting: doesn’t contain examples or demonstrations.
Prompt: Classify the text into neutral, negative or positive. Text: I think the vacation is okay. Sentiment: Output: Neutral - Few-shot prompting: provide demonstrations
Prompt: This is awesome! // Negative This is bad! // Positive Wow that movie was rad! // Positive What a horrible show! // Output: Negative - Chain of Thought Prompting: like
Let's solve this step by steporThink about this systematically - Role and Context Setting: like
You're helping debug code for a beginner programmerorAct as an expert physicist
In summary, clear role, prompt example and step by step instructions all can contribute to a good prompt.
Additionally, if you are developing a commercial LLM application, you may avoid prompt injection, because it attempts to manipulate the model’s behavior by including malicious instructions within seemingly normal input, similar as SQL injection.

Tool calling
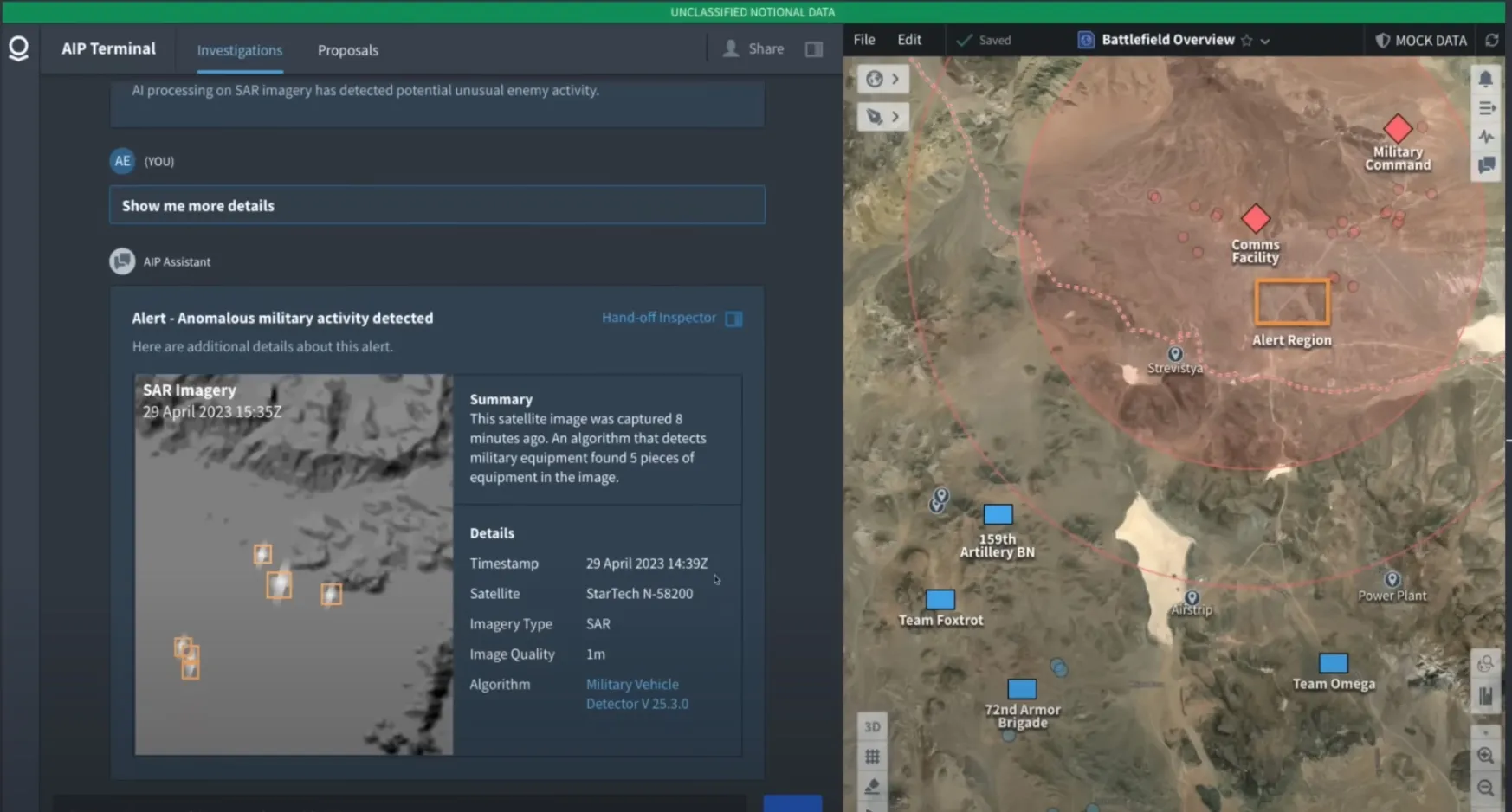 If you have watched Palantir’s Youtube Video, you may find out that the tool calling is hidden in the video. It is a good example of how to use LLM to call tool that process the information and return the result. Here it calls the tools to display images or draw graphs. How to implement it will be mentioned in the last section.
If you have watched Palantir’s Youtube Video, you may find out that the tool calling is hidden in the video. It is a good example of how to use LLM to call tool that process the information and return the result. Here it calls the tools to display images or draw graphs. How to implement it will be mentioned in the last section.
What is RAG?
RAG stands for Retrieval-Augmented Generation. It is a model that combines the strengths of retrieval-based and generative models.
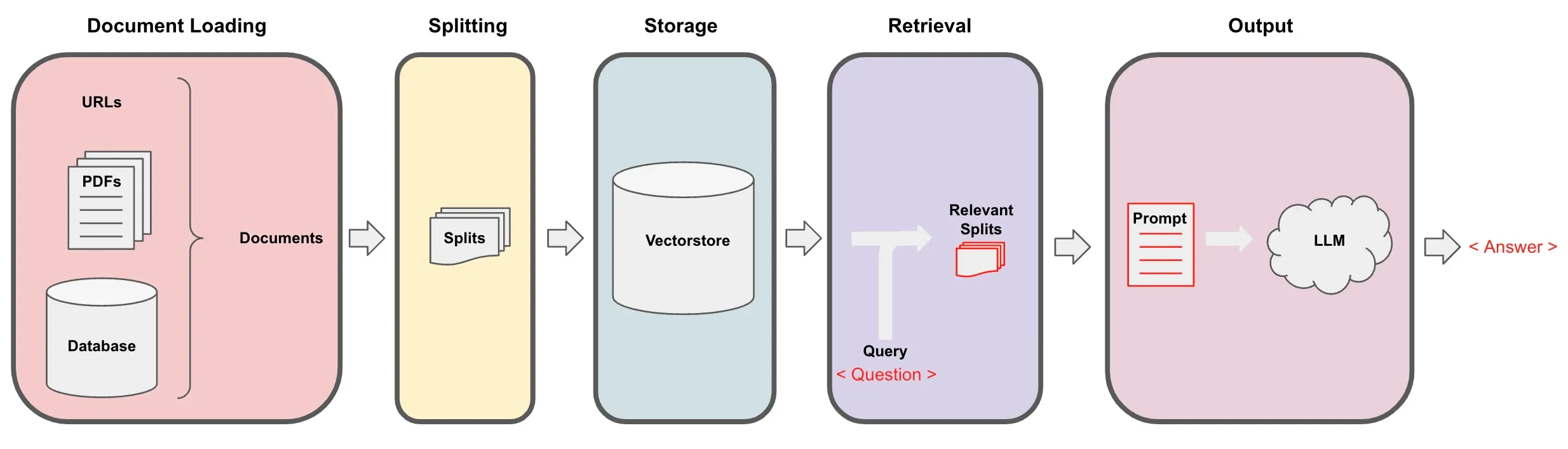
It consists of several steps:
- Document loading
- Document splitting
- Embedding
- Store in vectorstore
- Retrieve
In my github repo, there is an jupyter notebook file provided by DeepLearning.ai team, that explains well about each step. You can check it out here.
If you already know some about Database and vectorization of words, I can explain in one sentence:
When you retrieve, the query will be vectorized and compared with the vectorized documents in the vectorstore, then the most similar document will be retrieved.
What is ReAct?
ReAct is inspired by the synergies between “acting” and “reasoning” which allow humans to learn new tasks and make decisions or reasoning.
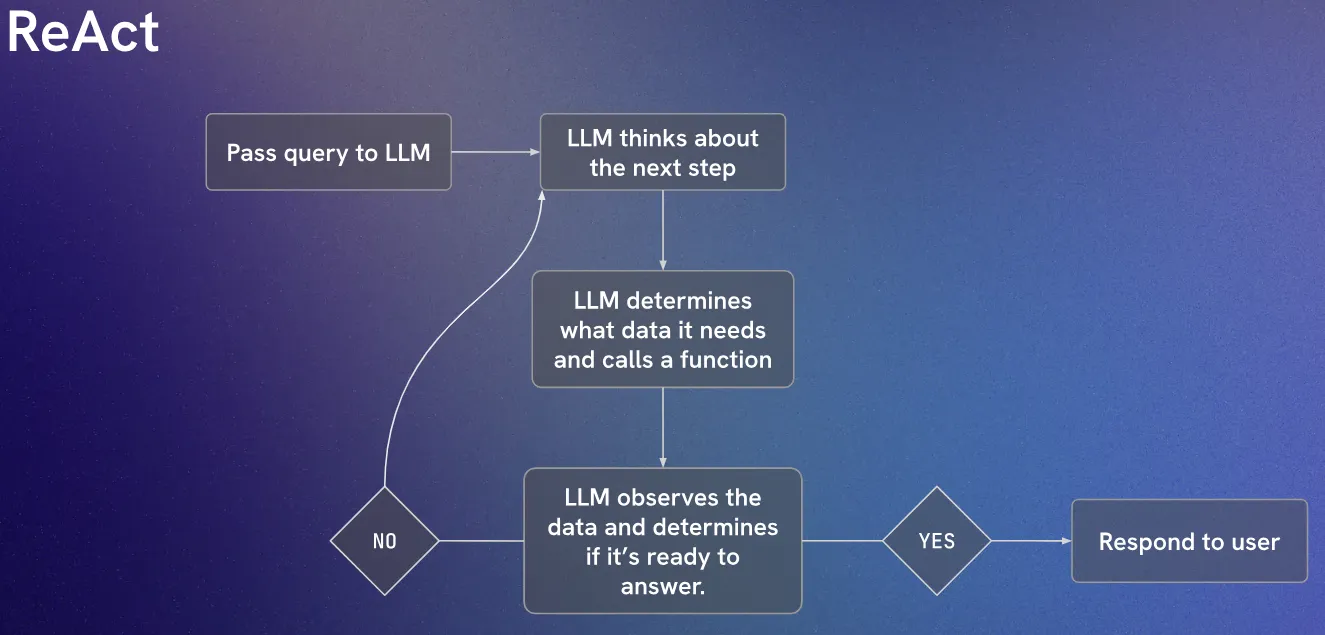
Its core concepts are:
- Combines Chain-of-Thought (CoT) reasoning with task-specific actions
- Uses a “Thought/Action/Observation” cycle
- Enables better decision-making through structured reasoning
One example could be:
Thought: I need to find X. Let me search for it first.
Action: Search[X]
Observation: Found information about X...
Thought: Based on this, I should now...
Action: ...I created ReAct agent based on Gemini and LangGraph, which uses tool to find the answer to the question user requests, you may want to check it out. A detailed explanation is coming in the next section.
Demo of Traditional RAG and Agentic RAG, ReAct Agent
I have created a demo of Traditional RAG and Agentic RAG, ReAct Agent (Gemini and LangGraph). Let’s discuss about the coding and some techniques we skip in the previous sections
Compared to Gemini, LangGraph is more complex but more structured. It uses a graph to store the information and retrieve the information. It has a steep learning curve but is more powerful.
ReAct Agent
ReAct in LangGraph is pretty simple, it provides create_react_agent function to create the agent directly. So here I will use the Gemini as an example.
The code flowchart is:
- People query
- llm thinks about what tool to use
- Call tool
- Judge result, if not good, repeat 2-4, if good, return result
To manage this, we need to create certain tools and functions, including:
- a nice system prompt with memory feature and tool feature, and generate response in json format (for easy data processing)
- decode the json response ( a simple function to change string to valid json data)
- a tool that llm can call ( here I use wikipedia search as an example, it contains several functions
search_wikipedia_pages,get_wikipedia_page_contentandget_wikipedia_page_summary) - a tool calling and result composing function that handles different tool calling actions, results returning and history storing. (This can be separated into different functions, but I put them together for simplicity)
Since ReAct is a loop, you’d better set a max iteration to avoid infinite loop.

From the ReAct result, you can tell the agent uses certain tool to search the information and return the result. Each step it provides reasoning and action.
Traditional RAG
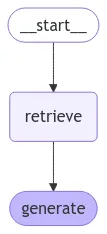 Here the
Here the retrieve node uses the vectorstore generated from the Document loading->Document splitting->Embedding->Store in vectorstore process. And generate node uses the LLM model to generate the answer.
To build the graph is very simple,
from langgraph.graph import START, StateGraph
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()after this you can use graph.invoke({"question": "YOUR_QUESTION"}) to get the answer.
Following tutorial provided by DeepLearning.ai, I created an interactive UI chatbot that uses memory to store the conversation history.

You can tell that the second question is related to the first question, which is a good demonstration of the memory function. Similarly, the third question is related to the second question.
Agentic RAG
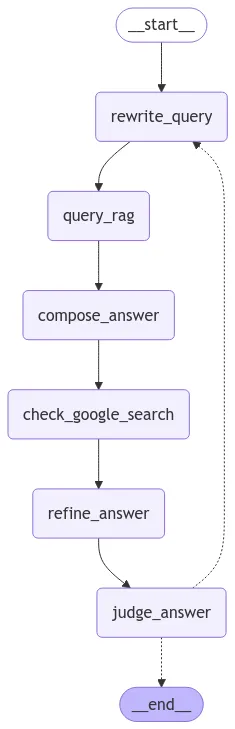 In the agentic RAG, several agents are used:
In the agentic RAG, several agents are used:
- rewrite query agent: to rewrite the query in a more structured way
- retrieve agent: to retrieve the information and call retrieve tool (yes, here we use retrieve as a tool)
- compose agent: to compose the information retrieved into answer
- check google search agent: decide whether to use google search or not given the result generated by the compose agent
- refine answer agent: to refine the answer generated by the compose agent and google search result
- judge answer agent: to judge the answer generated by the refine answer agent, if not satisfied, it will call the retrieve agent again to repeat the whole process.
The graph is built in the same way as the traditional RAG, but with more agents and more complex logic.
Click to see the code
class RAGState(TypedDict):
messages: list[AnyMessage] # adapt to MessagesState
original_query: str
current_query: str
retrieval_results: list[str]
answer: str
rewrite_prompt = ChatPromptTemplate(
[
(
"system",
"""You are a helpful research assistant that rewrites queries to fit the research purpose.\n \
The new query should based on the previous retrieval results and answers.\
If it is first iteration, simply optimize the query.""",
),
(
"human",
"""Here is the initial question: {original_query}, \n \
Here are the previous retrieval results: {retrieval_results}, \n \
Here is the previous answer: {answer}, \n \
Formulate an improved question:""",
),
]
)
answer_prompt = ChatPromptTemplate(
[
(
"system",
"You are a RAG agent. Use the retrieved context to answer the query comprehensively",
),
(
"human",
"""Here is the query: {current_query}\
Here are the retrieval results: {retrieval_results}\
Answer the query based on the retrieval results:""",
),
]
)
judge_prompt = ChatPromptTemplate(
[
(
"system",
"""You are a grading assistant, \
you judge whether the answer is satisfactory given the query asked.\
if it's not satisfactory, you ask for a requery.\
if it's satisfactory, you respond to user directly.
The response should be in json format, including two fields: \
- "needs_requery": boolean, whether the answer needs to requery\
- "reason": string, the reason for the judgment\
""",
),
(
"human",
"""Here is the query: {current_query}\
Here is the answer: {answer}\
Is the answer satisfactory?""",
),
]
)
google_tool_prompt = ChatPromptTemplate(
[
(
"system",
"""
You are a helpful assistant that can use tools to answer user's questions. \
You can decide to use tool or not
""",
),
("user", "{current_query}"),
]
)
google_search_answer_prompt = ChatPromptTemplate(
[
(
"system",
"""
You are a research assistant\
refine the answer given the query and some research paper content and google search result.\
the main content should be the research paper content, only add in google search content when necessary.\
""",
),
(
"human",
"""
This is the query: {current_query}\
This is the research paper content: {answer}\
This is the google search result: {google_search_results}\
You should refine the answer:
""",
),
]
)
# rewrite query to fit research purpose
def rewrite_query(state: RAGState) -> RAGState:
"""Rewrite the query to produce a better question"""
msg = rewrite_prompt.invoke(
{
"original_query": state["original_query"],
"retrieval_results": state["retrieval_results"],
"answer": state["answer"],
}
)
llm = ChatOpenAI(model="gpt-3.5-turbo")
response = llm.invoke(msg)
state["current_query"] = response.content
print(f"===== Rewrite Query =====")
print(f"New Query: {state['current_query']}")
return state
# query rag or respond
def query_rag(state: RAGState) -> RAGState:
"""Generate tool call for RAG or respond"""
llm = ChatOpenAI(model="gpt-3.5-turbo")
llm_with_tools = llm.bind_tools(
tools=[retrieve_from_vectorstore],
tool_choice="retrieve_from_vectorstore",
)
response = llm_with_tools.invoke(state["current_query"])
state["messages"] = [response]
print("===== Query RAG =====")
print(f"tool call: {response.tool_calls}")
return state
retrieve_tool = ToolNode([retrieve_from_vectorstore])
# compose answer
def compose_answer(state: RAGState) -> RAGState:
"""Compose the final answer"""
state["retrieval_results"] = state["messages"][-1].content
llm = ChatOpenAI(model="gpt-3.5-turbo")
msg = answer_prompt.invoke(
{
"current_query": state["current_query"],
"retrieval_results": state["retrieval_results"],
}
)
response = llm.invoke(msg)
state["answer"] = response.content
print("===== Compose Answer =====")
print(f"tool result: {state['retrieval_results']}")
print(f"Compose Answer: {state['answer']}")
return state
# check google search
def check_google_search(state: RAGState) -> RAGState:
"""Check if google search is needed"""
llm = ChatOpenAI(model="gpt-3.5-turbo")
llm_with_tools = llm.bind_tools(
[google_search],
tool_choice="auto",
)
msg = google_tool_prompt.invoke({"current_query": state["current_query"]})
response = llm_with_tools.invoke(msg)
state["messages"] = [response]
print("===== Check Google Search =====")
print(f"tool call: {response.tool_calls}")
return state
google_tool = ToolNode([google_search])
# refine answer with google search
def refine_answer(state: RAGState) -> RAGState:
"""Refine the answer with google search"""
state["google_search_results"] = state["messages"][-1].content
llm = ChatOpenAI(model="gpt-3.5-turbo")
msg = google_search_answer_prompt.invoke(
{
"current_query": state["current_query"],
"answer": state["answer"],
"google_search_results": state["google_search_results"],
}
)
response = llm.invoke(msg)
state["answer"] = response.content
print("===== Refine Answer =====")
print(f"tool result: {state['google_search_results']}")
print(f"Refine Answer: {state['answer']}")
return state
# judge answer
def judge_answer(state: RAGState) -> RAGState:
"""Judge whether the answer is satisfactory"""
llm = ChatOpenAI(model="gpt-3.5-turbo")
msg = judge_prompt.invoke(
{
"current_query": state["current_query"],
"answer": state["answer"],
}
)
response = llm.invoke(msg)
json_response = json.loads(response.content)
print("===== Judge Answer =====")
print(json_response["reason"])
if json_response["needs_requery"]:
return {"next": "rewrite_query"}
return {"next": "end"}
# define the function to determine to continue or end
def should_continue(state: MessagesState) -> Literal["rewrite_query", END]:
"""Determine whether to continue or end"""
message = state["next"]
if message == "rewrite_query":
return "rewrite_query"
return END
graph_builder = StateGraph(RAGState)
graph_builder.add_node(rewrite_query)
graph_builder.add_node(query_rag)
graph_builder.add_node(compose_answer)
graph_builder.add_node(check_google_search)
graph_builder.add_node(refine_answer)
graph_builder.add_node(judge_answer)
graph_builder.add_edge(START, "rewrite_query")
graph_builder.add_edge("rewrite_query", "query_rag")
graph_builder.add_edge("query_rag", "compose_answer")
graph_builder.add_edge("compose_answer", "check_google_search")
graph_builder.add_edge("check_google_search", "refine_answer")
graph_builder.add_edge("refine_answer", "judge_answer")
graph_builder.add_conditional_edges(
"judge_answer",
should_continue,
{"rewrite_query": "rewrite_query", END: END},
)
graph = graph_builder.compile()Similarly, I created a chatbot that uses memory to store the conversation history. However, since this is a research assistant, and the tool added is GoogleSearch, the result becomes less focused on the research paper content and more general.

The GoogleScholar API in LangGraph has bugs at the blog post time, so I used GoogleSearch instead. But I believe the GoogleScholar API will be more powerful and more focused on the research paper content.
Conclusion
This blog demonstrates some applications of LLM, RAG and ReAct, which shows the potential of LLM agents. It can help to search information in a wide range, or from certain PDF / WebPage / CSV files, use memory to chat with users, and call tools to process data and return the result.
Once we have a well formatted low-level tool collections (which you can tell LangGraph is already doing it), it can basically do everything we want, since most of the items in our life are coded and connected to the internet.
Written by Kristin Wei
← Back to blog