Published on Fri Jan 17 2025 00:00:00 GMT+0000 (Coordinated Universal Time) by Kristin Wei
This blog summarizes the basic concepts of reinforcement learning based on Sutton’s book.
Reinforcement Learning
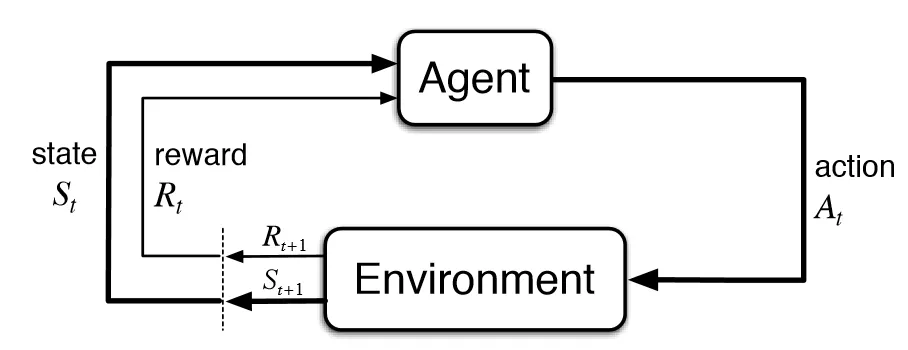 Reinforcement learning (RL) is an interdisciplinary area of machine learning and optimal control concerned with how an intelligent agent should take actions in a dynamic environment in order to maximize a reward signal. Reinforcement learning is one of the three basic machine learning paradigms, alongside supervised learning and unsupervised learning. [From wikipedia]
Reinforcement learning (RL) is an interdisciplinary area of machine learning and optimal control concerned with how an intelligent agent should take actions in a dynamic environment in order to maximize a reward signal. Reinforcement learning is one of the three basic machine learning paradigms, alongside supervised learning and unsupervised learning. [From wikipedia]
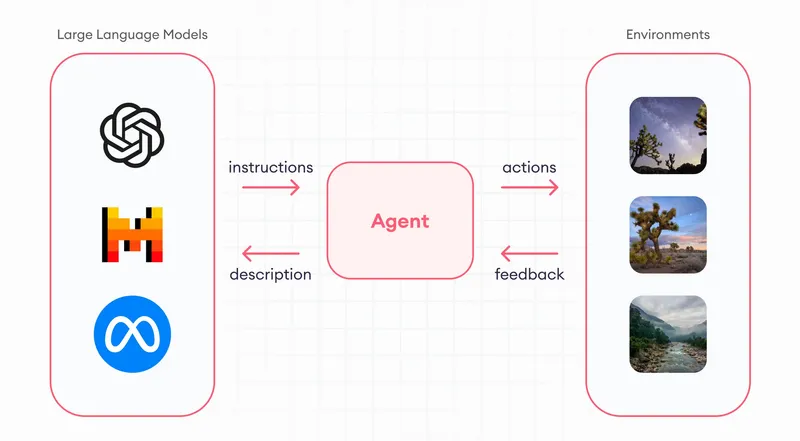
Simply, an agent (robot) interacts with an environment (world) and learns to make decisions to maximize its final goal. Here,
- the reward is the the feedback from the environment.
- final goal is the optimization goal of the whole learning process.
There are some famous algorithms in RL, such as Q-learning.
About DRL we will mention in another post.
Fundamentals
Basic Concepts
Reinforcement learning bases on :
-
: state value, often used in model-based method;
-
: state-action value, often used in model-free method;
- why state-action: is defined partly in , and are all parameters inside agent, consequently, is a combination of and .
-
: the policy of a agent, chose a (action) at a state;
-
: reward, got from each step
-
: a time-scale reward recording, or a estimate of value for current state.
- : Terminal time
- : a self-defined parameter to look how much further into future — long future reward would not affect that much,but instant does.
- From the equation, the is influenced by and , but for a well-behaved future-telling agent is usually set to 1or 0.9, which indicates, for a self-made envornment, should be set properly to obtain a wanted training result.
An Example: Hero in a game
A hero in game collects coins(reward) along a path in a 2d grid map to gain experience.

-
Real Existing Items:
Once the hero has the real items, it can absolutely get the max reward from environment.
- represents how many future values the position has, (even is also self-defined, but in my view, doesn’t affect that much.)
- and is what the hero gets from each step in the environment.
-
Estimate:
Estimate is what the hero guess about the , which is . But obviously, in an environment, is related to state and time, when the hero is exploring with a policy. Then should be , that’s what we get from training.
- - value function
- - action-value function
These 2 are generally the same with , since basically the policy always exist for most of the agent. The only difference is now they are estimate for with policy .
The FAMOUS Bellman Equation
The Bellman equation is basiccally connecting the and , or and ,
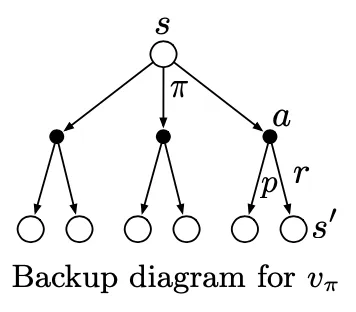
Similarily explained above, will become for , then the Bellman equation changes to:
Choose Path based on Bellman Equation
When the hero stand at state seeing all , but only one step will be chosen in reality, which means for this action . This decision will let the biggest, and the policy will be updated and is defined as:
is of course not controlled by the hero, thus, policy has the only option in next step — at choose , where is max for all . Use the same logic,
v(s) vs q(s,a)
seems have chosen the without policy. But thinking deeply, policy controls the choice when finally the hero acts in the environment. The for and just dedicates the policy is updated according and .
No matter which is used in policy update, what really matters is the next state , the or the , since again the is not controllable.
Once the next step is determinated, at this state is also confirmed. just more connects to the next state.
choses the path by comparsion between multiple , but indicates the path by comparsion between its company .
RL Methods
Monte Carlo, Temporal-Difference and Q-Learning are all model-free methods, which means the probability departing from states to states is unknown. The above optimal policy is used in Dynamic Programming, since the is known. That’s also the reason why use DP in model-based environment. For model-free environment, the value is estimated by exploring and update. MC, TD or Q-learning just differ at these 2 processes.
Monte Carlo
The basic idea of Monte Carlo is to estimate value by :
in the step update form:
with starting from , in Monte Carlo .
With this setting, Monte Carlo performs the best with full exploring, also means for on policy MC control with -soft algorithm, and must run enough steps, which is absolutely slow!!!
Using this idea, of course in most environments, exploring start with argmax at policy update will fail.
Nevertheless, the is driven from trajecotry updated by , where the Terminal . No terminal then no value update and policy update. However, a random walk can’t garante reaching the terminal.
α-constant Monte Carlo
The - constant Monte Carlo updates it by:
In - constant will always consider part of the original : 3
for , when , has more value depending on , and specially recent .
What’s more, when updating the value, the value is moving towards to the actual value, no matter is updated by Monte Carlo average method or TD or Q-learning, so partly we can trust the new .
Temporal Difference
TD is a bootstrapping method, which is quiet determined by the old value.
Comparing with the - constant Monte Carlo , is the stepsize and also determines the update quantity of the . Once is estimated close to the real value, is updated by one step closer to the real . Digging to the end, the terminal , and the s are all updated exactlly by one step close to the real value, unlike the Monte Carlo, always needing a trajectory to end to update the value.
For TD, update is not deserved with end to terminal. The first run to terminal is only updated valuable on the , and next run is , and so on…
On one side, the is updated truely along the way to terminal, with this chosen path, the value is updated more fast, since the agent prefers to go this path under - greedy policy; On the other side, with randomly exploring, the agent searchs for a better way to terminal. Once found the new path will be compared with the old one, the will determine the optimal path.
If we use in TD, then the algorithm is called the famous sarsa.
Similarly, the is updated from the once reaches the terminal.
Q-learning
While the agent is still randomly walking in the environment without arriving at the terminal, then the updated value is equavalent to random initialized . The meaningful value is like TD starting from , the difference locates at that, because of the continous exploring, we can safely choose the best way with fast speed. This indicates we can determine the best step from state by looking into the s and gives the a symbol () that is the best within his company:
Gradually the from the starting state, the agent find the fast by seeing the biggest at each state.
Thoughts
Arbitrary Initial Q or V
Even give or a positive value at start, by updating, a negative value or will contribute part of it. At least the will definately affect negatively to it. After this, a positive or can’t be compared with a , which is driven from the positive value given by terminal.
Where goes p(s’,r|s,a) ?
When we have the model, then can help us compare the by avioding the low value and passing more though the high value, or directly getting more rewards. In model free, there is no in offer. But no matter or or just to find the best way. With many exploring, the value is showing the best probability of getting best reward, then there is no need to setting in model free environment.
is of course not controlled by the hero.
Epsilon Greedy vs Epsilon Soft
In reinforcement learning, we can’t run infinite times to update the whole - value table or - value table, efficient update choices must be made.
Generally thinking, which or has more opportunity to get (high value), should be updated more to converge to the optimal. But stochastic exploring is also required to jump out of sub-optimal. The simple idea to implement is -greedy.
Tips:
To generate a list of probability of action set, which sum to 1, we can use Dirichlet distribution, e.g.
p=numpy.random.dirichlet(np.ones(n_actions))
epsilon -Greedy
i.e, random chose with and chose the best with
with code
p[max_value_index]=1-epsilon
p+=epsilon/nepsilon - Soft
the only requirement of - Soft is each probability greater than , Dirichlet is useful here.
p=np.random.dirichlet(np.ones(n))*(1-epsilon)
p+=epsilon/nFootnotes
Written by Kristin Wei
← Back to blog